Recent developments in generative models and large-scale datasets have substantially advanced 3D world generation, facilitating a broad range of domains including spatial intelligence, embodied intelligence, and world modeling. While achieving remarkable progress, existing approaches to 3D scene generation typically prioritize appearance prediction with limited modeling of the underlying geometry, leading to issues such as unreliable scene structure estimation and degraded cross-view consistency.
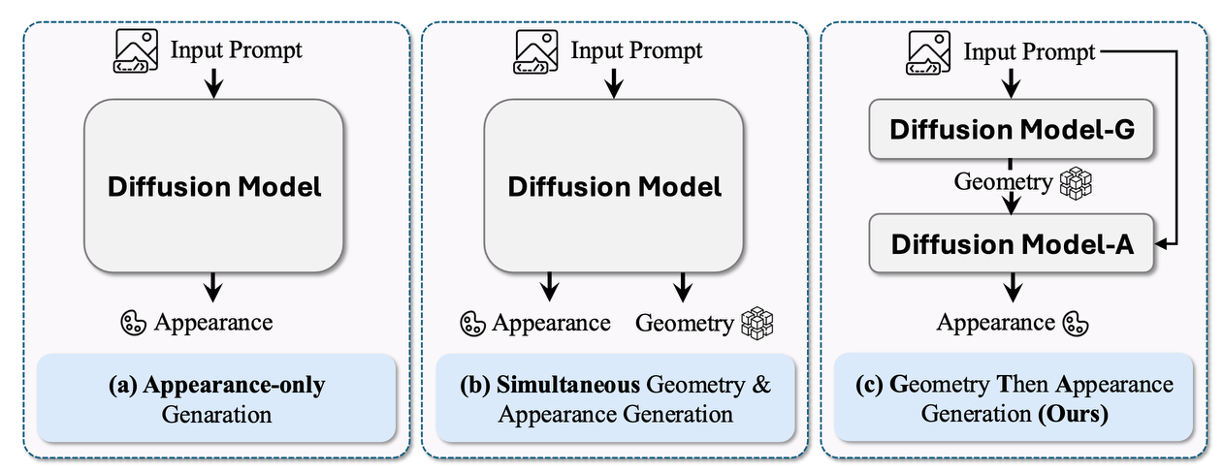
To address these limitations, motivated by the coarse-to-fine nature of human visual perception, we propose GTA, a novel image-to-3D world generation method following a
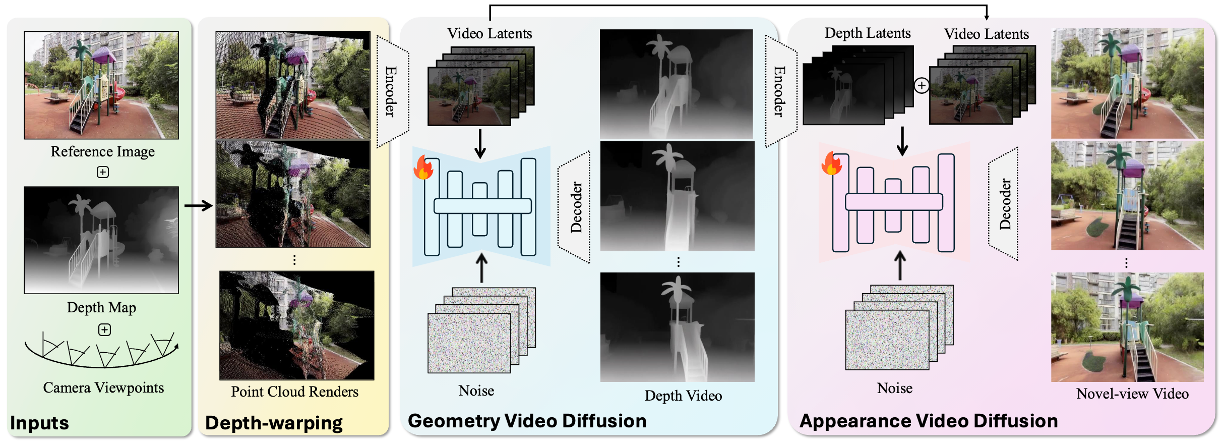
Geometry-Then-Appearance paradigm. Specifically, given a single input image, to improve the structural fidelity of synthesized 3D scenes, GTA adopts a two-stage framework with two dedicated video diffusion models, which first generate coarse geometric structure from novel viewpoints and then synthesize fine-grained appearance conditioned on the predicted geometry.
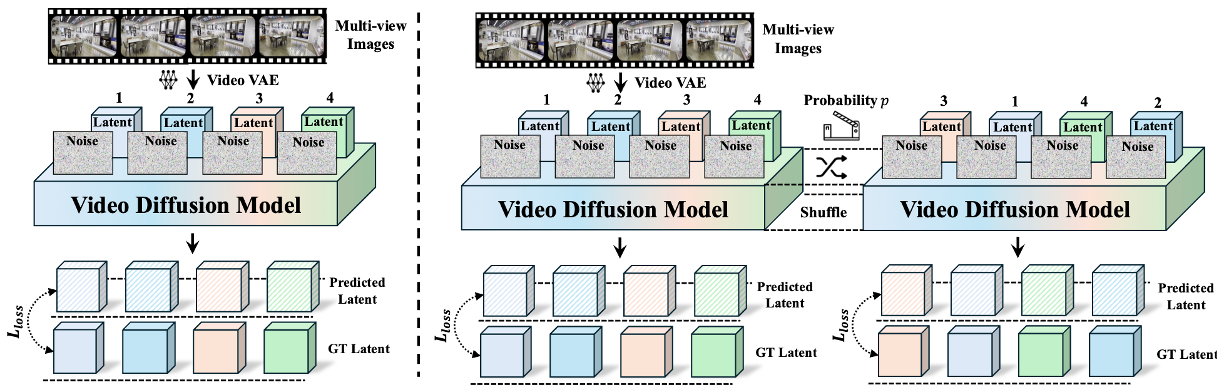
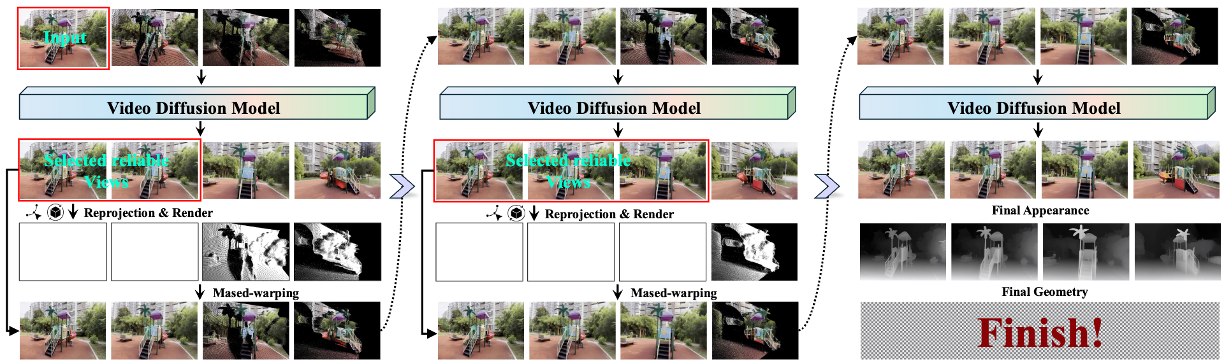
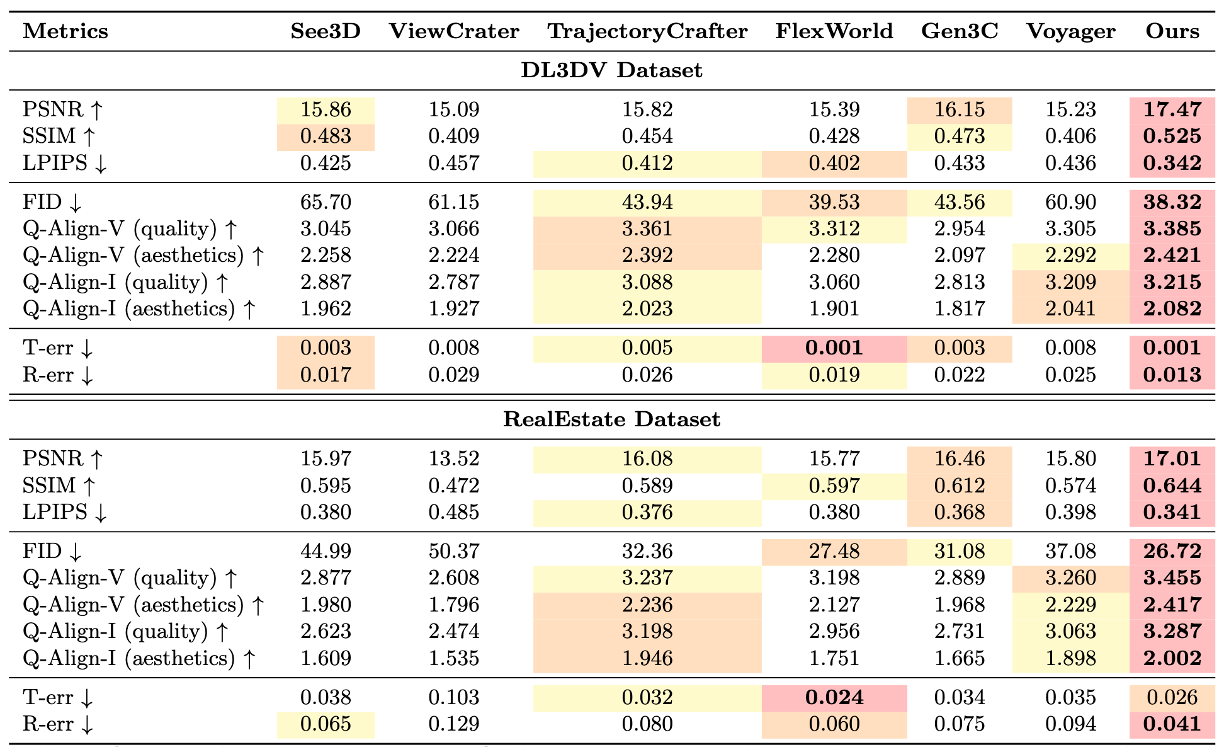
To further enhance cross-view appearance consistency, we introduce a random latent shuffle strategy during the training process, along with a test-time scaling scheme that improves perceptual quality without compromising quantitative performance. Extensive experiments demonstrate that our proposed method consistently outperforms existing approaches in terms of fidelity, visual quality, and geometric accuracy.
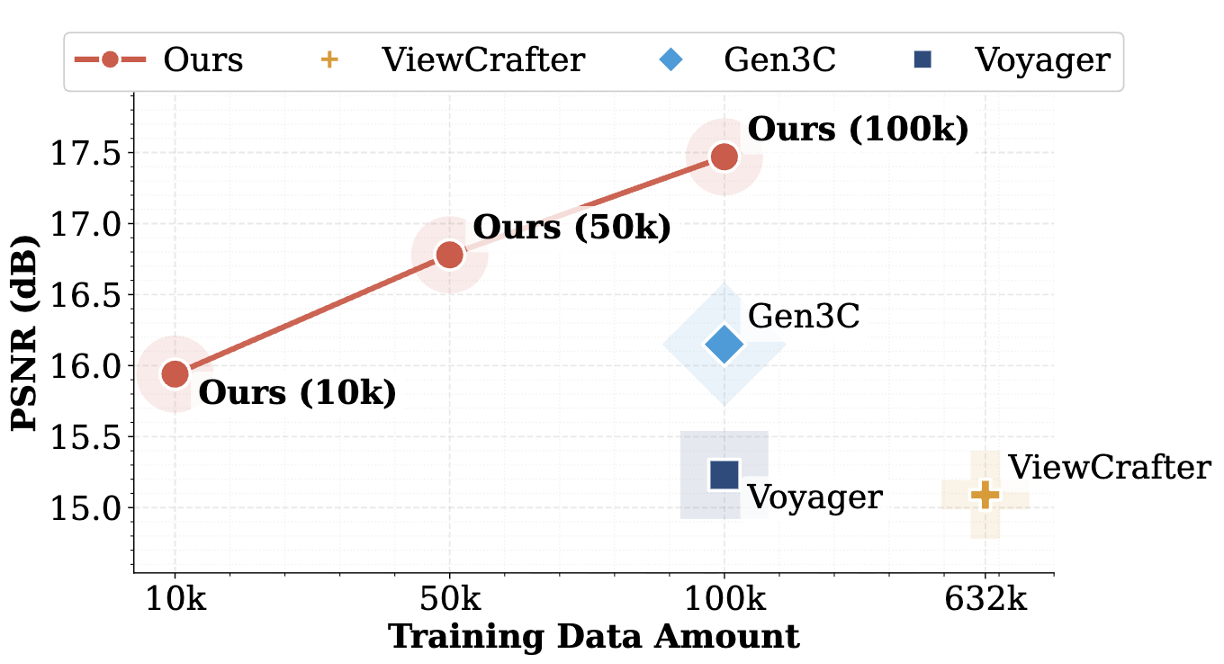
Moreover, GTA is shown to be effective as a general enhancement module that further improves the generation quality of existing image-to-3D world pipelines, while also supporting multiple downstream applications and exhibiting favorable data efficiency during model training, highlighting its versatility and broad applicability.